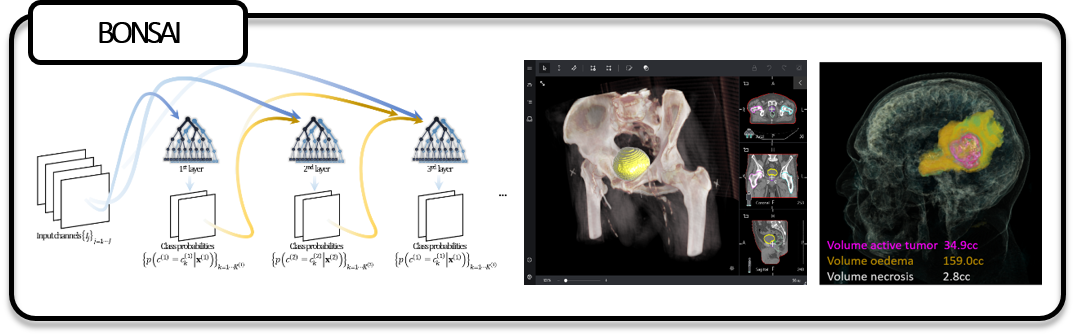
I’ve been working on this project as a researcher in the InnerEye team at MSR Cambridge, where I develop image processing and machine learning solutions for medical image analysis. The BONSAI framework is a fast CPU-based machine learning C++/C# solution for medical image segmentation tasks, and uses Decision Forests as a building block.
A surprising limitation of ‘vanilla’ Decision Forests is that they are not easily capable of semantic reasoning, and BONSAI addresses this in a practical way. Organs of interest in medical images have much structure. They typically deviate in but a few plausible ways from their mean shape. Anomalies might have more complex patterns of variability, but also display obvious structure (they are generally spatially localized). The location of organs relative to each other, or sub-structures within organs, is also variable but constrained. Hence when trying to make sense of the content of an image, it is natural for us to supplement ambiguous image information with semantic spatial context. If we are confident about assigning a given label to a subset of voxels, it can be used as a powerful cue from which to decide label assignments of neighbouring voxels.
Vanilla segmentation forests however are only capable of intensity-based contextual reasoning. We introduce semantic reasoning via auto-context, cascading layers of decision forests whose output, along with the raw intensity maps, form the input to subsequent layers. This is possible thanks to the efficiency with which individual layers are trained (seconds to minutes). In particular at each node, the information gain-based feature optimization is replaced with a criterion based on cross-validation estimates of generalization error. This is seamless, fast and yields a natural mechanism to control tree complexity (tree pruning) and generalization.
Finally, we use a form of guided bagging after initial layers, whereby latent clusters are identified within the training data and cluster-specific subforests are trained. For previously unseen data, cluster assignments are computed and points are tested through their cluster-specific subforest. Clusters are learned in an unsupervised manner from the latent semantics already captured within a previous decision forest layer. Each data point is identified with the collection of tree paths that it traverses, and the decision pathways are clustered. The intuition is that data points will share common semantics whenever clustered together, as they jointly satisfy many predicates.